新材料的研发能力与国家核心创新能力和国家安全密切相关。然而长期以来,以研究经验为主的实验试错研发模式导致材料研发周期长、成本高,是制约新材料研发的关键因素。近年来,随着人工智能技术的快速发展,利用自然语言处理技术(Natural Language Processing, NLP)自动地从科研文献中获取知识信息已成为现实。区别于传统通过人工阅读文献获取信息的方式,“AI读论文”能够帮助材料科学家更加精准高效地从大量科学文献中获取材料描述信息,从而快速发现材料组成结构和性质之间的复杂关系。
虽然基于AI技术的知识发现给材料科学带来重大机遇,但是在实现过程中也存在诸多挑战。首先,文献原文使用人类语言进行内容表达,重要的化合物名称和表征结果等信息隐藏在上下文的描述信息中,如何从非结构化的文献内容中提取和表示目标信息的内在关联是影响模型性能的关键环节。其次,信息提取模型的准确性验证需要大量手动标注的数据,而手动标注耗时费力且难以覆盖庞大的材料领域信息,缺乏统一的评价标准。
针对上述挑战,本文使用无监督的词嵌入方法skip-gram构建词向量空间,从330万篇材料学领域文献摘要中获得约50万200维的词向量,基于深度学习模型能够有效地提取和表示文献中的材料学知识,并预测具有潜在热电性质的材料。
在自然语言处理领域,词嵌入模型能够提取单词特征并将其映射到高维向量,相似的词具有相似的向量编码。本文先探究了在材料文献库和语法文献库的类比任务中对skip-gram、连续词袋模型(CBOW)以及GloVe模型评估,并在相应的模型训练时加入了材料文献库中Method(方法)部分,表示为+phrases。结果如图1所示,其中skip-gram+phrases模型取得最高的评分,因此作为后续材料性质预测的词嵌入模型。
图1 算法选择:在材料文献库和语法文献库的类比任务中进行算法评估,每个任务包含约15000个类比对。Default(默认算法)使用Word2vec;四种Word2vec变体模型使用优化后的超参数;GloVe算法使用原始论文的推荐参数。
基于skip-gram+phrases模型生成100个化学元素词向量后,使用t-SNE(t-distributed stochastic neighbor embedding)投影至二维平面并绘制图像。如图2所示,具有相似化学性质的元素聚合能够生成类似元素周期表的基本结构,初步表明具有相似词向量的化学物质可能具有相似的化学性质,并包含从文本学习到的“材料信息”。
图2 (a)100种化学元素名称的词向量通过t-SNE在二维平面投影,可以看到分组后化学上相似的元素聚集并呈现出类似元素周期表(b)的结构。从左上到右下依次是是碱金属、碱土金属、过渡金属和稀有气体。
为了进一步探究材料学领域材料词向量及其性质之间的关系,作者以LiCoO2和LiMn2O4为例,使用深度学习模型,输入单词向量可以获得该单词上下文可能出现的词的概率,通过分析经常在相似上下文语境出现的化合物可以得到具有类似性质的材料。在图3中,经过对上下文出现单词概率归一化后,发现在LiCoO2和LiMn2O4上下文的单词种类和概率大多相同,这表明二者具有类似的材料学性质。
图3 在高维稀疏的材料数据词向量空间中,LiCoO2和LiMn2O4其对应的词索引处为1(例如图中的5和8位),其他地方为零。对于类似的电池正极材料,在材料文献中出现的上下文词大多相同(例如“阴极”、“电化学”等)。
热电材料因其污染小、寿命长等特性作为新环保能源替代材料,近十年来,多种新型热电材料在材料学文献中相继被报导。在这些文献中,当某种化合物的词向量和“热电”词向量的余弦相似度较高,即表示该材料可能出现在描述热电性质的段落中。然而当文献库中并没有二者同时出现的段落时,一些未被发现的具有热电属性的新型材料则可能被“预测”出来。
在文章中,作者筛选材料文献库词频大于3,并同时出现在密度泛函理论(DFT)计算热电效率因子数据集的9483种化合物,其中7663种在之前的文献报道中从未与热电领域关键词共同出现过,因此被视为可能具有热电性质的候选材料。图4a表示Li2CuSb和Cu3Nb2O8被预测为具有热电性质的材料,但未在文献中被报导;而在前10项预测的候选材料中,其分布如图4b所示,所有计算出的热电效率因子都略高于已知热电材料的平均值(17.0 μW K-2 cm-1)。
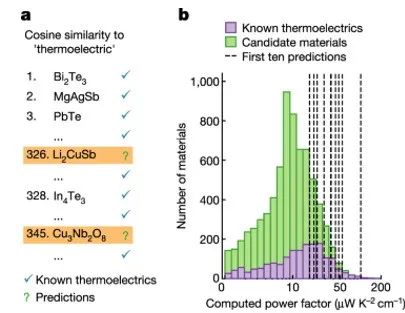
图4 (a)使用化合物的词向量与“热电”词向量的余弦相似度进行排名,尚未被报导(橙色)具有热电应用且排名靠前的材料被认为可能具有潜在的热电性能材料;
(b)使用DFT计算的热电效率因子数据集,包含1820种已知热电材料(紫色)和7663种尚未报道具有热电属性的材料(绿色)。
为进一步验证使用无监督算法预测新型热电材料的可行性,作者搜集从2001至2018年共18个热电材料历史数据集,并基于过去报道的材料词向量来预测在未来最可能出现的前五十种热电材料。在图5a中,对每一个历史数据集的预测结果计算准确度产生灰色的数据。绘制逐年累计的预测准确率变化曲线(红色),发现比DFT计算预测的结果准确率(绿色)高三倍。图5b中,基于2009年之前发表的文献数据集预测结果前五名中,有三种化合物被后续报导为热电材料,其中CuGaTe2仍是当今最好的热电材料之一;而HgZnTe和SmInO3两种化合物由于造价和毒性等原因尚未进行研究。
图5 (a)从热电材料历史数据集中预测未来出现的热电材料结果。灰线代表使用该年之前发表的摘要进行预测,在图像中绘制了预测材料在之后几年被报导为热电材料的累积百分比;由于数据集大小的偏差,这部分的结果在横向准确性对比效果缺乏可信验证,早期的预测可以在更长的测试周期内进行分析,从而产生更长的灰线;
(b)来自2009年数据集的前五名预测结果,星号标记表示该材料作为首次作为热电材料被报导的年份。
在本文中,作者基于材料学文献数据集,使用skip-gram模型分析材料和属性描述词的共现关系,通过词向量的相似性度量,在未预先输入材料领域知识的情况下,即可根据从文献中获得的材料知识发现潜在的热电材料。近年来,随着科学文献发表量的增加,机器学习和深度学习方法在传统材料化学领域交叉应用实例不断涌现,挖掘论文数据中的非结构信息能够为研究人员提供丰富的先验经验,减少高昂的实验试错成本,形成基于AI智能技术的研究领域知识发现新范式。
2020级博士后
研究方向: 单分子智能科学仪器研制和知识发现研究
")
