文献分享:控制小组
ICLR:专家经验的引导让强化学习学会探索
Making Efficient Use of Emonstrations to Solve Hard Exploration Problems

文章导读
本文介绍了R2D3算法1,该算法可以有效利用专家数据演示来解决在不确定性初始条件下强化学习无法有效探索学习的问题。本文还演示了此算法在八种应用场景中的控制效果,并证明了R2D3可以提高探索效率,解决其他SOTA(state of the art,截止目前最先进的算法)算法无法解决的稀疏奖赏问题。
该文预印版来自于arXiv预印平台,该平台的存在是造就科学出版业进行开放获取运动的主要因素。现今的数学家和计算机学家习惯于将其论文先上传至arXiv.org,再提交给专业的学术期刊。在该平台系统下,作者首先要得到一位领域知名学者的背书或者领域权威机构的认可才能在该平台进行文章的上传。
引言
本文中,研究者的应用场景有以下特点:(1)初始状态高度不确定(2)奖赏稀疏,智能体无法从所有空间状态获取有效奖赏。
因此对于这类场景,强化学习的训练将会面临以下挑战:
(1) 稀疏奖赏带来的探索陷阱问题,即在稀疏奖赏的情况下,在大部分状态空间中智能体无法取得有效反馈,将导致探索效率极其低下;
(2) 局部状态会导致智能体陷入局部最优的困境,无法找到全局最优控制策;
(3) 初始状态的不确定性会导致强化学习的探索学习困难,一般情况来说,初始状态不变有利于强化学习的学习效率,因为固定初始状态来进行轨迹跟踪可以使得强化学习的探索效率极大提高。
研究人员在本文中将专家信息指导与RL(Reinforcement Learning)相结合,使得智能体能够高效地探索学习,而且在本文的演示实验中,R2D3算法的学习效率明显优于行为克隆的模仿学习方法。
方法
R2D3全称Recurrent Replay Distributed DQN from Demonstrations,顾名思义,研究人员在DQN(Deep Q-learning)的基础上首先加入了循环神经网络,然后在加入循环神经网络的基础上加入了专家经验(Demonstrations)引导。那么为什么要加入这两个改进机制?我们首先通过下图来解答引入Demonstrations的理由。
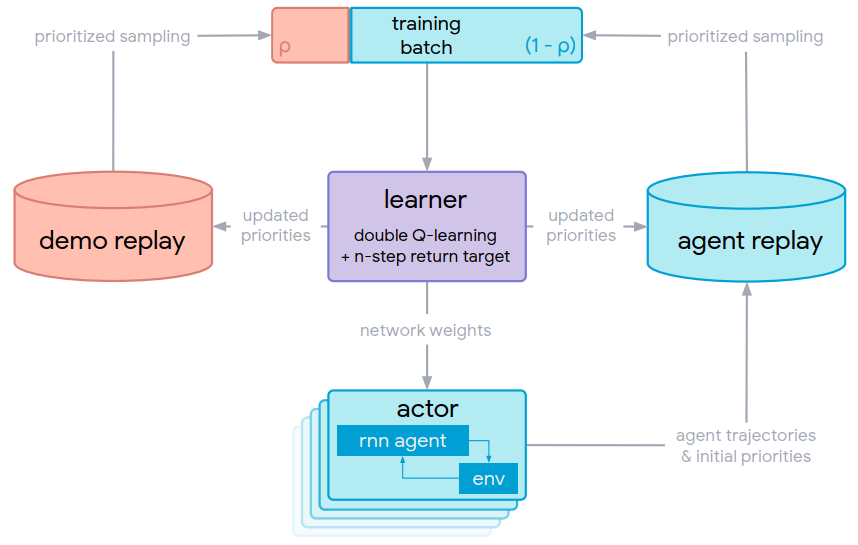
图1 R2D3分布式系统图
如上图所示,R2D3由五个部分组成,第一部分是动作网络,本中采用的是分布式DQN,第二部分是专家经验的演示信息池,第三部分是DQN的交互数据信息池,第四部分是更新规则,第五部分是批样本采集池。同一般的 mini-batch 不同,R2D3的 mini-batch 来源于两个部分,一部分是来自 demo-replay 的专家演示数据,这部分数据由LQR或者MPC这一类控制算法提供(这些传统控制算法对于单一目标轨迹控制效果较好,且结构较为简单),另一部分来自 agent-replay 中的智能体和环境交互产生的实时数据。现阶段强化学习异步策略的训练方式都是利用信息池中的信息对智能体网络进行更新学习,因此融合了专家信息的 mini-batch 就可以为智能体提供更加优质的轨迹信息,同时又可以保证智能体从实时数据中学到探索的策略,既保证了学习的稳定收敛又保证了算法的探索需求。该信息池改进方法的数学描述如下: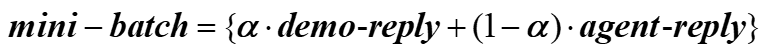 ,α代表 mini-batch 中专家经验的占比,根据实验经验,在本文中α取值为0.25。接着我们再看算法的细节部分:
,α代表 mini-batch 中专家经验的占比,根据实验经验,在本文中α取值为0.25。接着我们再看算法的细节部分:
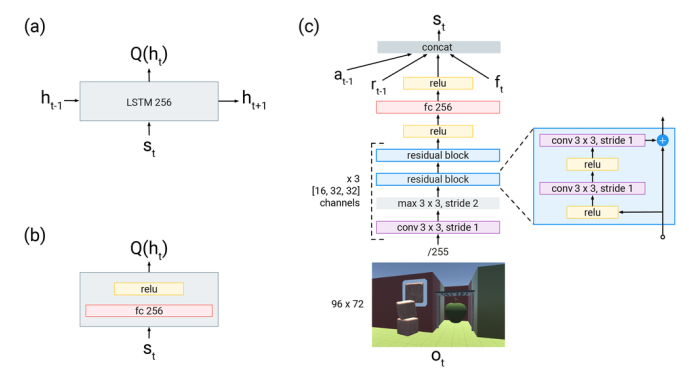
图2 (a)R2D3算法使用的循环神经网络;(b)DQfD使用的全连接神经网络,(a)和(b)均用于计算状态价值;(c)R2D3网络整体架构。
上图(a)表示R2D3使用了LSTM(Long Short-Term Memory)来构成价值网络的输入层,为什么这样做?是因为LSTM能够存储历史的参数信息,因此可以记忆整个探索空间中的状态行为,这解决了不确定性初始状态带来的探索学习困难的问题。上图(b)是DQfD算法价值网络,是一个常见的全连接层,通过relu 激活函数给出输出,其没有存储历史信息的功能。上图(c)是价值网络的整体架构,由卷积神经网络提取图像信息作为状态传入价值网络。而价值网络的更新以及动作的选取则与2014年的DQN论文一致2。DQN伪代码如下:

首先初始化记忆信息池D用于存储交互过程产生的信息,初始化价值网络和目标价值网络。开始进行7~13行任务。首先根据ε-greedy的选择动作at,执行动作at 获得奖赏rt 和下一个状态st+1 ,存储交互信息。执行第13行计算损失函数,接着进行梯度下降优化网络参数。这就是DQN的优化框架。R2D3算法框架如下:

结果
研究人员在以下八个环境状态进行了实验证明:

图3. 实验环境,八个实验环境分别为网球, 过桥, 冰块漂流, 推箱子, 记忆传感器, 过十字路口, 墙体传感器, 壁面传感器(从左到右从上到下)
实验结果如下:
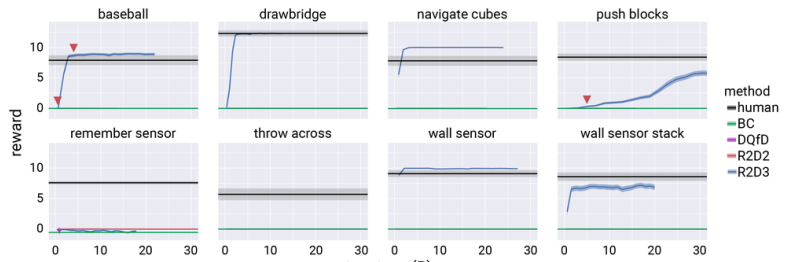
图4 Hard-Eight任务套件上R2D3的奖励与基线算法的性能对比。
上图描述了Hard-Eight任务套件上R2D3的奖励与基线算法的差异。将这些曲线基于每个任务5个不同种子进行随机实验所绘制而成。误差区域显示了算法平均收益95%的置信区间。R2D3可以在棒球,吊桥,导航多维数据集和墙壁传感器上达到人类水平或更高的水平。R2D2无法在任何任务上获得任何积极的回报。相比之下,DQfD3(Deep Q-learning from Demonstrations)和BC(behavior cloning)算法偶尔会在Drawbridge和Navigate Cubes任务上得到奖励,但在大部分场景中无法获得奖赏,以至于在图中看不到训练效果。
结论
在本文中,研究人员介绍了R2D3算法,该算法旨在有效利用专家信息在稀疏的奖励和不确定性初始条件下在状态观察缺失的环境中进行有效学习。
本文通过对八个非常困难的任务的反复实验证明了该算法能够有效克服奖赏稀疏以及不确定性初始状态的控制问题。
算法的结果分享表明,R2D3利用专家信息对智能体进行有向引导的自主探索的方式有利于智能体的探索学习。这也说明专家信息的引导是改善RL探索效果的有利条件,也为之后的研究提供了技术方向。
参考文献
1 Paine, T. et al. Making Efficient Use of Demonstrations to Solve Hard Exploration Problems. ICRL (2020).
2 Mnih, V. et al. Human-level control through deep reinforcement learning. Nature 518, 529-533, doi:10.1038/nature14236 (2015).
3 Hester, T. et al. Deep Q-learning from Demonstrations. ICRL (2017).
原文链接:https://arxiv.org/abs/1909.01387
撰稿人:徐星海(2018级硕士生)
校稿人:文柯超(2019级硕士生)
")
