控制小组文献分享
ICML2020: 基于样本效率的多智能体协同进化强化学习

摘要
许多多智能体协作强化学习场景为智能体提供了稀疏的基于团队目标的团队奖励,以及密集的基于单个智能体技能的个体奖励。团队奖励被用于激励智能体之间协作实现团队目标,而个体奖励被用于激励智能体学习基本的技能。通常,因为团队奖励是稀疏的,仅仅依靠它的训练策略是低效的,而仅仅依靠个体奖励的训练策略由于不能促进团队协调使得智能体容易陷入局部最优而达不到全局最优。本文介绍了多智能体进化强化学习(Multi-agent evolutionary reinforcement learning, MERL),它通过对多智能体种群进行进化,最大化稀疏的团队奖励,同时通过构建基于梯度的优化训练策略,最大化密集的个体奖励。基于梯度的策略被周期性地加入进化种群中,作为两个优化过程之间传递信息的方式。MERL能够让智能体使用由个体奖励学习到的技能实现团队目标。实验结果表明,在一些复杂的多智能体协作环境的测试中,MERL的性能明显优于多智能体深度确定性策略梯度算法(Multi-Agent Deep Deterministic Policy Gradient, MADDPG)、多智能体双延迟深度确定性策略梯度算法(Twin Delayed Deep Deterministic policy gradient algorithm,TD3)、进化算法(Evolutionary Algorithms, EA)等方法。
背景
多智能体协作环境通常会给予智能体基于团队协作目标的团队奖励以及奖励基本技能的个体奖励。例如,在足球比赛中,密集的个体奖励可以奖励球员的技能,如传球、运球和跑步。智能体间必须协调何时何地使用这些技能,以实现团队目标,即赢得比赛。通常情况下,个体奖励是密集的,容易学习,但由于需要所有或大多数智能体的合作,团队奖励是稀疏的。由于团队奖励的稀疏性,让每个智能体直接最大化团队奖励而忽略个体奖励通常会导致训练失败或对复杂任务的探索效率低下。传统方法,如MADDPG,让每个智能体直接最大化个体奖励的策略也是有局限的,因为这种策略没有促进团队协作实现团队目标,容易使智能体陷入局部最优而达不到全局最优。解决这个问题的一种方法是奖励设计,但在复杂的环境中设计合适的奖励本身就具有挑战性。奖励设计通常依赖于环境,需要环境相关的知识以及针对各个环境特点进行调整,还存在改变任务目标的风险。
内容
MERL的关键优势两在于,它是一种通用的方法,不需要依赖于对特定环境的奖励设计。这是因为MERL直接通过团队奖励来优化实现团队目标的策略,同时利用个体奖励来激励智能体学习基本技能。除此之外MERL在MADDPG与其他算法无法应对的复杂协调环境中具有很好的鲁棒性。
MERL的结构如图一所示,整个群体由M个多智能体团队组成,每个团队拥有相同的拓扑结构,并拥有随机生成的初始策略。每个团队中的第K个智能体共享经验池RK。各个团队在每个训练回合结束时得到团队奖赏,并将其视为这个团队对环境的适应度。群体在每个进化周期结束后进行进化,群体中的一部分团队将被选中生存下来,被选中的概率与团队的适应度成正比。之后将通过变异和交叉算子对群体中部分团队的策略进行进化,产生下一代团队。而适应度最高的一部分团队被视为精英团队被保留下来,不参与变异过程。在任何一段给定时间内,适应度最高的团队代表了此时完成团队任务的最佳策略。
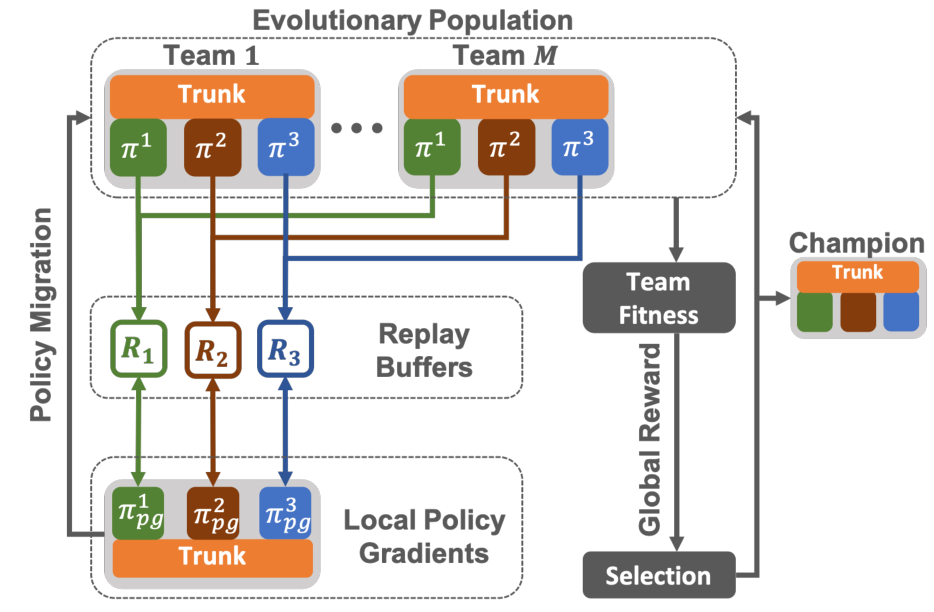
图1:MERL结构图
与只基于对团队奖励学习的传统进化算法不同,MERL在每个训练回合中还基于策略梯度(Policy Gradient)对经验进行学习。为了实现这种“局部学习”,MERL构建了一个多智能体策略网络πpg以及一个评价网络Q。加入噪声的πpg被用于引导它本身在每一个回合内的构建,同时将每个群体内智能体K的经验存储在经验池RK中。至关重要的是,每个智能体的经验池相互独立,以保证智能体的多样性。评价网络Q从每个经验池中随机地采集小批量经验基于梯度下降来更新自身的参数。之后每个智能体的策略网络πpgk从其对应的经验池RK中采集小批量的经验输入评价网络中得到策略梯度。与传统进化算法只以最大化团队奖励为目标不同,MERL寻求在最大化团队奖励的同时最大化个体奖励。
MERL的核心机制在于πpg网络被周期性地复制到进化群体中,并通过参与进化来传播其特性,这使得智能体通过团队奖励与个体奖励学习到的策略被结合在一起。且进化只保留被迁移网络的性能优化梯度,这种机制实现了对破坏性干扰的保护,这种干扰通常在尝试对奖励函数直接标量化时出现。此外,信息交换的程度在学习过程中自动调整,而不是依赖人工调整。
MERL的伪代码如下:

结果
研究人员在图二所示环境中进行了实验验证,得到了图三所示的实验结果
研者在实验中测试了MADDPG与MATD3的两种变体,global表示智能体只接收稀疏的团队奖励作为它们的强化信号。mixed表示智能体接受团队奖励与个体奖励的线性组合作为它们的强化信号,每一种奖励在组合前都经过了规范化。在基于各个耦合因子的场景中MERL的表现都显著优于其他算法,且在耦合因子大于3时各种算法的表现会明显变差。增大耦合因子相当于增大了联合空间探索的难度以及实现团队目标过程中各智能体动作之间的耦合,但是并不会使状态空间变大,也不会增加智能体运动的复杂度。这表明智能体性能的下降完全是由于智能体动作耦合程度增大。
值得注意的是,MERL是试验中唯一能够学习耦合因子大于6的环境的算法,而且使用了与其他算法相同的信息以及未经特殊处理的奖励函数。这主要是由于MERL使用了分层处理方法,这种方法允许它利用个体奖励来实现智能体的动作规划,同时利用团队奖励来实现智能体的协作。
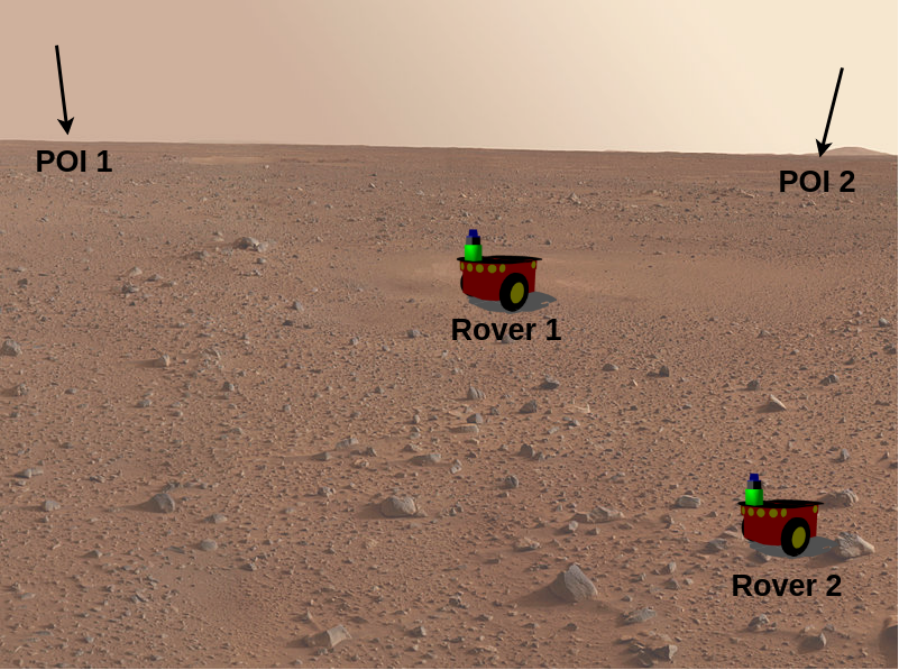
图2,Rover domain游戏

图3,图(a),(b),(c)分别表现了MERL,MADDPG,MATD3,EA算法在智能体间动作耦合因子为1,3,7的Rover domain游戏中的表现。横轴为训练的步数,纵轴为算法的相对性能。图(d)为图例
总结
在本文中,研究人员介绍了MERL算法,这种算法旨在利用分层处理的方法在团队奖励稀疏的复杂多智能体协作环境中进行有效学习。本文对比通过智能体间耦合程度不同的环境下各种算法的表现证明了MERL算法能够实现在高耦合复杂多智能体协作环境下的控制。
原文链接:https://proceedings.icml.cc/paper/2020/hash/d5cfead94f5350c12c322b5b664544c1-Abstract.html
撰稿人:肖钟毓(2020级硕士生)
校稿人:徐星海(2018级硕士生)
")
