智能控制小组
Nature:通向通用人工智能-一种基于模型的强化学习算法

背景
AlphaZero[1]通过零基础自学,在已知规则的情况下经过4小时训练就打败了国际象棋顶级AI-Stockfish,2小时的训练就打败了日本将棋顶级AI-Elmo,8小时的训练就能够打败了与李世石对战的AlphaGo。这些成绩都证明AlphaZero已经成为最顶级的棋牌AI。AlphaZero解决了以下挑战:在已知规则的指导下了解如何进行游戏,解释了每个棋子的移动方式。然而我们知道AlphaZero是在知道规则的前提下才能够进行自我学习,同时只能游玩棋牌游戏,在面对其他游戏环境时仍然需要重构智能体架构。而MuZero[2]的诞生,成功弥补了AlphaZero的缺陷,向通用人工智能迈进了一大步。
MuZero与之前工作的对比
图1 是DeepMind所开发的四种游戏AI的比较图。
最初的AlphaGo在训练之中可以得到人类经验、专家数据以及游戏规则,通过蒙特卡洛树搜索算法规划下棋策略。但其状态、蒙特卡洛树的构建只针对于围棋环境,只能够玩围棋这类游戏,无法得到普适应用。
AlphaGo Zero在AlphaGo 的基础上加入了自我博弈的功能,使得智能体能够自我产生学习数据,脱离专家经验的限制,但其状态信息以及决策架构任然基于围棋,因此仍然只能游玩围棋。
当进入到AlphaZero时期,研究者为了提高算法的普适性做出以下改进:
(1) 采用Resnet代替了卷积神经网络,Resnet是现阶段描述能力最强的神经网络架构,其具有124层神经网络,几乎能够对任何函数进行拟合.
(2) 将强化学习结构中的策略梯度算法更换为策略迭代算法,通策略迭代算法减少了对策略梯度的计算,大大提高了算法的运行效率。
通过以上两点改进,AlphaZero能够在已知游戏规则的条件下游玩三类棋牌游戏,需要注意的是面对不同游戏环境时,AlphaZero并不需要重构算法结构。
AlphaZero智能体通过同一个框架可以游玩不同种类的棋牌游戏,但在不知道规则的情况下同样无法游玩游戏,不仅如此其只能游玩具有相似策略形式的棋类游戏,无法延伸到其他游戏领域。而MuZero在无需知道任何专家经验以及游戏规则的情况下,可以随意游玩包括雅达利2000在内的多种游戏,成功打开了通用人工智能的大门。而下文就会为大家揭开MuZero的面纱,解释其为何具有如此强大的泛化能力以及学习能力。
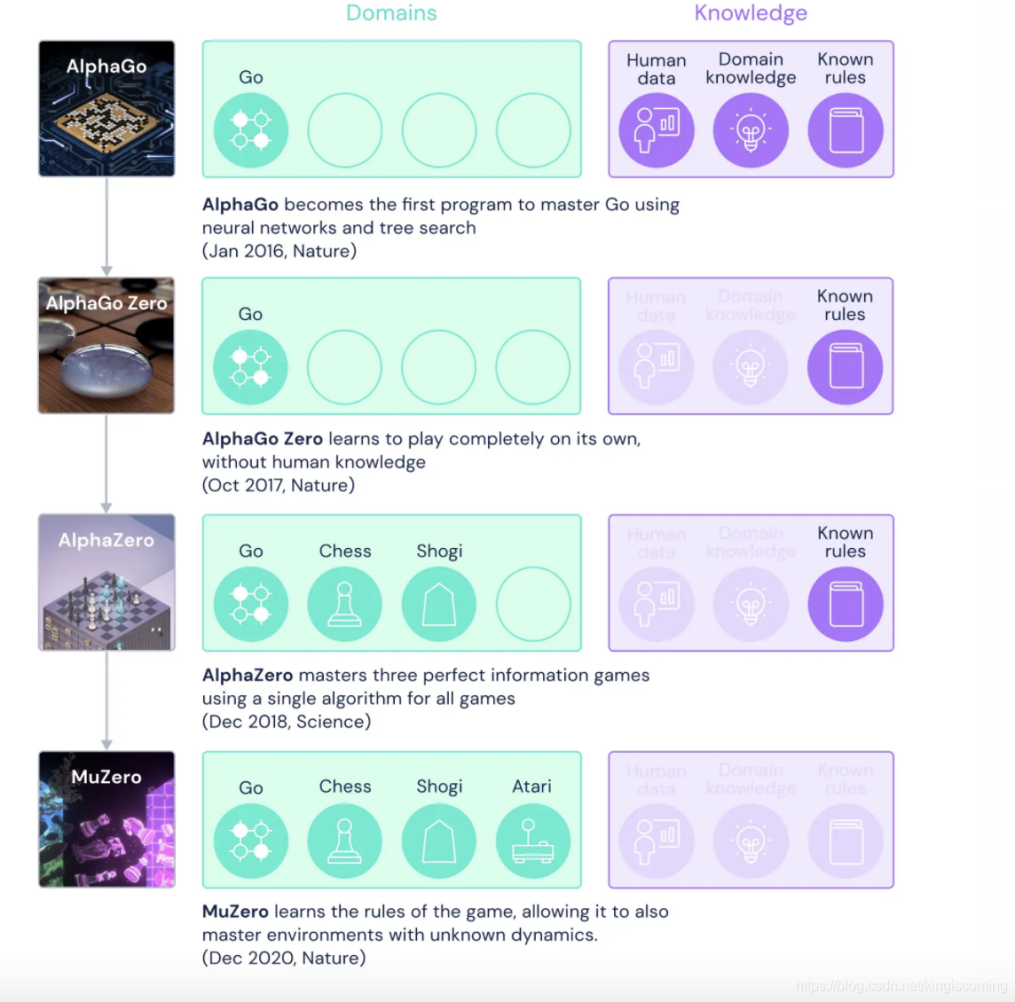
图1 DeepMind四类游戏AI的差异
方法
MuZero之所以能够取得如此巨大的进步在于其使用了基于模型的强化学习算法,当然AlphaZero中已经使用了类似思想,但MuZero相较于AlphaZero的进步在于下表:
表1 MuZero所使用的模型概览

如表1所示,MuZero拥有三个神经网络模型,三种网络的作用如下所示:
(1) 其中表达模型对环境状态进行数据清洗,使得策略网络能够快速的识别状态信息,加速强化学习的训练效率。
(2) 动态模型可以拟合环境规则。这就是为什么MuZero在不知道游戏规则的情况下也能够学习到游戏策略,这是因为MuZero通过动态模型可以拟合出未知游戏的游玩规则。
(3) 预测模型对策略进行评价,在这里的预测网络就类似于强化学习中的价值网络,为策略提供对未来的预测,进而优化游戏策略。
理论上三个网络的耦合能够对任意未知的信息进行预估,而AlphaZero只拥有预测网络模型,在不知道规则的情况下无法对动作进行预估,同时也无法为策略提供对未来的估计。
MuZero三个网络结合的框架也是基于蒙特卡洛树搜索的方法,其框架如图2所示:
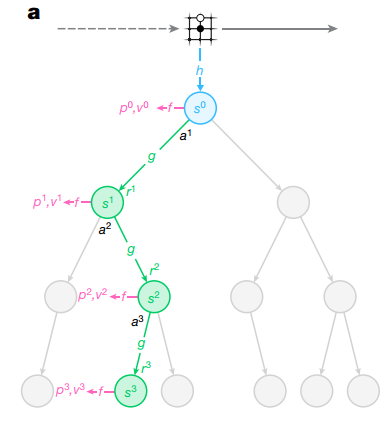
图2 蒙特卡洛树搜索结构图
其中h为表达模型,f为预测模型,g为动态模型。表达模型对实时状态进行预处理,将其转为预测模型和动态模型能够理解的数字型编码,预测模型通过编码后的状态预测出最优动作以及状态价值,动态网络估测预测网络给出的最优动作的即时奖励,通过重复此过程直到动态模型判定游戏结束,最终得到当前实时状态所应该采取的最佳动作。
同时,为了加速框架的训练效率,三个网络使用同一个损失函数:
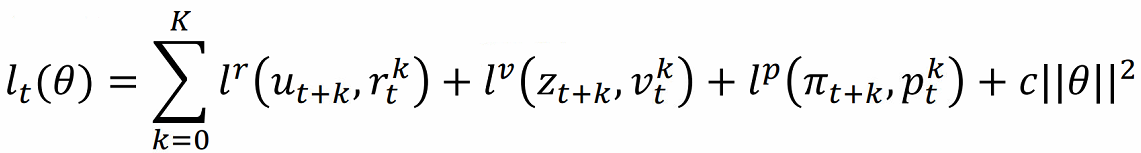
该损失函数就是对预测误差求导,这样设置网络的损失函数有利于快速进行反向传播,提高算法的整体效率。
而动作的选取也是蒙特卡洛树搜索的经典选取方法:
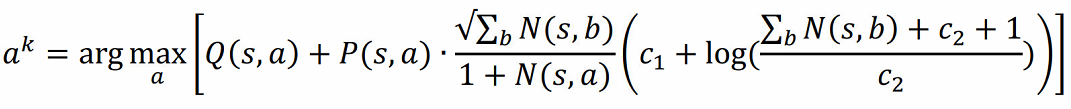
对于每一个源自状态s的动作a,都会有与之对应的状态信息(s,a),其中N表示被访问的次数,Q表示平均价值,P表示策略,R表示奖励,S表示状态。动作a就是通过最大化平均价值Q进行选择。
结论和意义
如图3所示,图的上半部分是对应游戏环境,下半部分中黄色曲线为AlphaZero的基线水平,蓝色曲线为MuZero的游玩水平,从结果上来看,MuZero通过基于模型的强化学习方法,在围棋,象棋等棋牌游戏以及 Atari 游戏中都取得了超过之前的SOTA(state of the art,效果最好的算法)或与SOTA持平的效果。
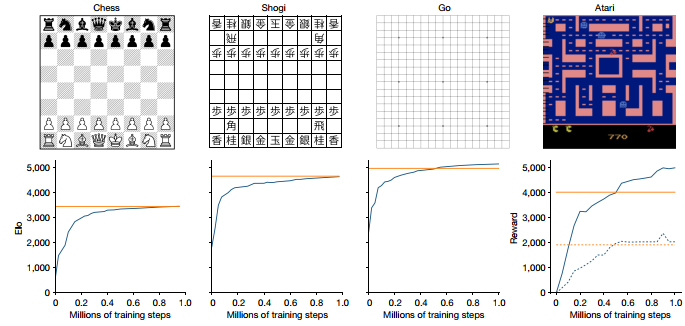
图3 结果对比图
众所周知由于数据利用效率很差,强化学习在游戏化境之外的应用面临很多问题,效果一向不甚理想,而 DeepMind 这个工作作为基于模型的强化学习的新进展,其大大推动了RL在真实环境中应用研究的发展,同时也是通用人工智能的新一步。
引用文献:
[1] Silver D, Hubert T, Schrittwieser J, et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play[J]. Science, 2018, 362(6419): 1140.
[2] Schrittwieser J, Antonoglou I, Hubert T, et al. Mastering Atari, Go, chess and shogi by planning with a learned model[J]. Nature, 2020, 588(7839): 604-609.
原文地址:http://www.nature.com/articles/s41586-020-03051-4
撰稿人:徐星海(2018级硕士)
校稿人:马成栋(2020级硕士)
")
