控制小组文献分享
AAAI:基于保守策略和演员-评论家框架的高效模型强化学习

一、前言
基于模型的强化学习通过和真实环境进行交互得到的数据来拟合一个环境模型,并且根据拟合模型进一步学习如何决策。相较于无模型的强化学习算法,基于模型的强化学习算法通常具有高样本效率。但是高样本效率同样受到模型的制约,特别是模型不准确时,强化学习算法不但不能提高样本效率,反而会学到错误的决策。而对于复杂且伴随噪声的环境来说,学习到一个精准的模型是非常困难的。以前的方法是通过学习Q值的近似下界来进行保守估计以减小模型误差的影响,比如说鲁棒策略优化法就是取一组模型最小的Q值来进行策略学习。这些方法会学习到过度保守的策略,严重降低了它们的样本效率和渐进性能。因此,本文提出一种保守的基于模型的演员-评论家算法(conservative model-based actor-critic,CMBAC),在不依赖精确模型的情况下来实现高样本效率。
CMBAC会从一组不准确的模型中学到Q值函数的多个估值,并使用最小的k个估计值的平均值来优化策略。这种保守的策略可以避免智能体去选择那些仅仅在一小部分模型中估值较高却不安全行动。仿真实验表明CMBAC在多个复杂任务中的表现明显优于SOTA(state of the art)算法,并且在噪声环境下具有更好的鲁棒性。
二、背景
本节介绍在强化学习领域一些基础的概念以及其常用符号。首先定义这样一个元组(S,A,P*,r,γ,ρo),来表示在无限时域上的马尔可夫决策过程,其中S和A分别是状态和动作的集合;P*:S×A×S→[0,∞)是状态转移概率密度函数,P*(·∣s,a)表示在给定当前状态s以及动作a时下一状态的条件分布;r:S×A→R为奖赏函数;γ是折扣因子;ρo:S→[0,∞)是起始的状态分布。设π:S→P(A)是一个稳定的策略,其中P(A)为动作空间A上所有动作的概率,π(·∣s)表示在状态s下A的概率分布。基于模型的强化学习算法根据与真实环境交互得到的数据来学习一个动态模型P^(·∣s,a),这是一个典型的后验概率分布,即在有观测数据的基础上某一事件发生的概率,在此处表示已知当前状态为s,动作为时a,估计下一时刻所有状态的概率分布。设So为随机的初始状态,Q^π,P为模型P和策略π上的状态-动作价值函数,那么它可以表示为:
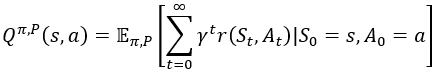
定义η=(π,P)=Eπ[Q^π,P(So,Ao)]为预期奖赏,算法最终的目标就是在真正的模型上获得最大的预期奖赏,即通过策略π最大化η(π,P*)。
三、算法设计
CMBAC算法中以下两个过程会交替进行:
1. 通过一组模型学到Q值函数的多个估值;
2. 使用最小k估计的平均值来优化策略。
其算法的伪代码如下所示:

(一)捕捉Q值的不确定性
由于不能完全精准模拟复杂的真实环境,Q值必然不能被准确地计算出来。为了量化这种不确定性,CMBAC使用了多个神经网络拟合的多个模型来进行估算,即将状态转移概率建模为高斯分布的模型,通过神经网络来给出每个模型的期望与方差。在算法中使用N个神经网络拟合近似模型,从中随机抽取M(M<N)个网络共同参与构建出一个模型,每个模型表示为Mj,那么就可以根据当前的(s,a)生成下一状态s'的概率:
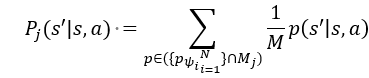
这样一组模型能够使用随机化的初始值,从而较好地逼近真实环境的后验分布。
有了环境的后验分布模型后,算法需要由此来近似Q值的后验分布。为了实现这个目标,CMBAC通过多头Q网络从模型的近似分布上学习多个估值,其结构如图1所示,其输入端为不同拟合模型根据当前的(s,a)生成下一状态s',输出端为估值Qθj,中间是共享的网络结构,CMBAC的目标是从多“头”的Qθj来估计Q^π,Pj,这样的设计可以显著提高计算优势,其中每一“头”Qθj(s,a)目标值为:
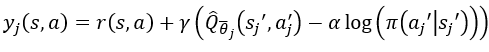
公式中Sj'采样自Pj(·∣s,a),aj'采样自π(·∣s),Qθj为网络参数为滑动平均值θj的目标值神经网络,其中的参数θj可以通过贝尔曼残差来训练:
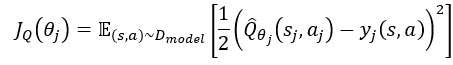
在本篇论文中,研究人员采用了两个多头Q网络,并且使用对应的两个“头”中较小的值来训练每一个“头”的值。这是一种比较经典的处理方式,可以有效避免Q网络在学习过程中的过估计问题。
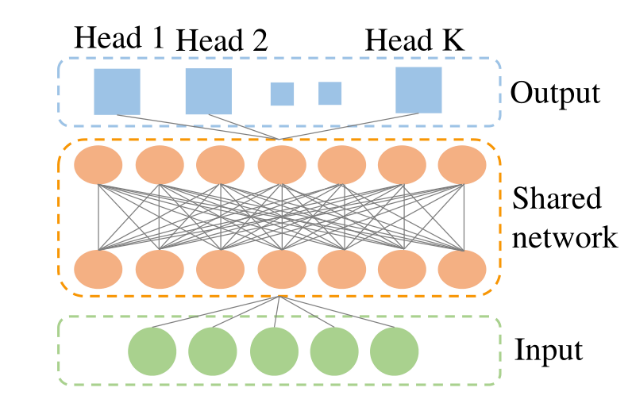
图1 带有K个头的多头神经网络示意图
(二)保守的策略优化方法
为了避免模型错误所导致的智能体负优化,CMBAC使用Q值的保守值估计来优化策略。将共计K个模型计算出来的Q值进行排序并且抛弃其中最大的L个,使用剩下的K-L个值进行来进行策略优化:
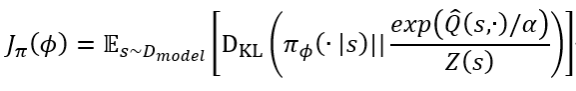
其中:
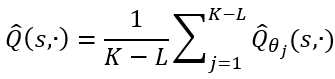
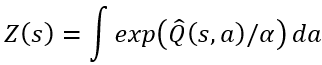
总的来说,CMBAC算法的整体框架如图2所示。当N=3,M=2,L=1时,CMBAC算法首先会学习三个概率神经网络并用排列组合的方式选取两个来生成模型,得到共计三个模型。然后对三个模型生成的Q值进行排序,抛弃最大的一个,用剩下的值来学习策略。
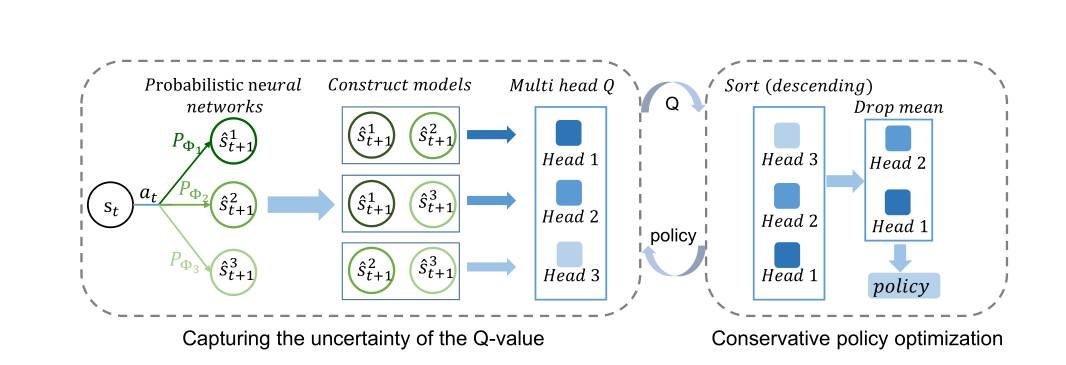
图2 N=3,M=2,L=1时CMBAC的示意图
(三)CMBAC的优点
1. 捕捉全局不确定性:根据一组模型的误差以及它对评论家学习的影响,CMBAC可以捕捉到全局的不确定性,因此能够处理模型长期预测误差带来的估值过高的问题。
2. 捕捉不同粒度下的不确定性:CMBAC可以通过改变M(每个模型中神经网络的数量)来控制分布近似的粒度,由此可以确定在不同粒度下的不确定性。
3. 灵活地调节保守的程度:CMBAC可以通过调节M和L来调节其保守程度,调节M可以改变保守程度的粒度,也可以通过增大L来提高它的保守程度。
四、实验验证
(一)性能测试
为了验证算法的样本效率,研究人员将CMBAC与四种强化学习领域的SOTA算法进行比较。这四种SOTA算法中两种为基于模型的强化学习,两种为无模型的强化学习,它们分别是:
1. 基于模型的策略优化算法(model-based policy optimization,MBPO);
2. 基于模型的离线策略优化算法的在线变种(online variant of model-based offline policy optimization,MOPO-Online);
3. 软演员-评论家算法(soft actor-critic,SAC);
4. 随机集成双Q学习算法(randomized ensembled double Q-learning ,REDQ);
将CMBAC与对照的算法学习在强化学习领域经典的六项任务,得到其平均估值如图3所示。可以发现在这六个任务中,CMBAC算法的表现均优于其余算法。在最复杂的Humanoid任务中,CMBAC的学习速度远远快于其他方法,它在20万步时的表现与MBPO在30万步和SAC在300万步上的表现相当。
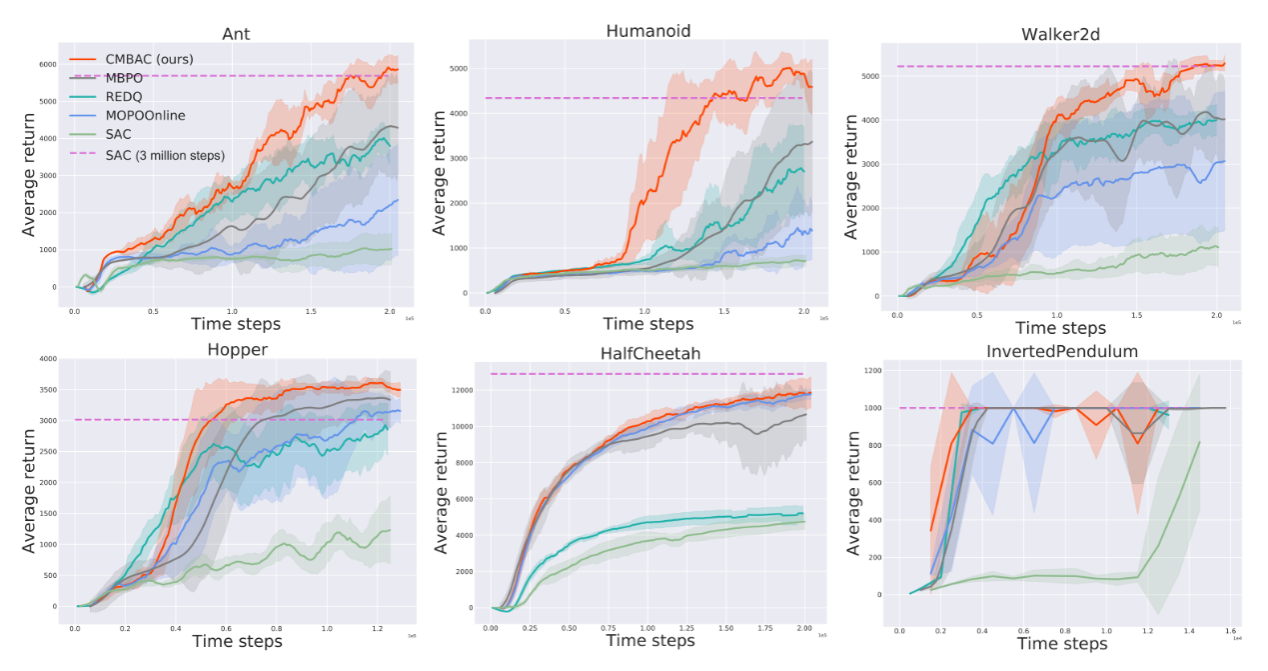
图3 CMBAC和四种经典算法在六项连续控制任务中的表现。实线对应于五个随机种子的平均值,阴影区域对应标准偏差
(二)消融实验
为了分析CMBAC的鲁棒性,研究人员将其与MOPO-Online和MBPO在嘈杂的Walker2d和HalfCheetah任务中进行了比较。在训练过程中,将标准偏差σ=0.1的高斯白噪声添加到智能体的每一步动作之中,其结果如图4所示。就在噪声环境中的采样而言,CMBAC明显优于两种算法。
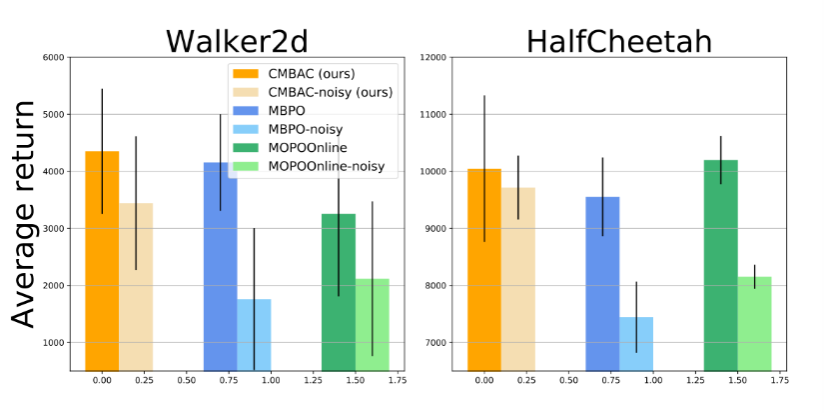
图4 CMBAC、MBPO和MOPO-Oline在嘈杂环境中的表现
五、总结
在本篇论文中,研究人员提出了一种保守的基于模型的演员-评论家算法(CMBAC),这是一种基于集合模型来估计Q值上的后验分布的新方法,并使用近似分布的左尾(统计数据经切割后较小的一部分)平均值来优化策略。实验表明,在几个复杂的控制任务中,CMBAC在采样效率方面都显著优于目前最先进的方法。此外,在噪声环境的测试中发现它比以前的方法具有更强的鲁棒性。
在之后的研究中,我们可以尝试借鉴CMBAC算法的框架,包括通过集合模型估计Q值以及对近似分布的取舍。另外其算法中是通过神经网络确定高斯分布的参数来构建模型,对于复杂环境来说可能计算量过大,也许可以将其更换为机理模型,仅用神经网络来确定模型中较为敏感的几个参数,从而减小计算的复杂度。
原文链接:
https://doi.org/10.48550/arXiv.2112.10504
参考文献:
[1] Wang, Zhihai et al., Sample-Efficient Reinforcement Learning via Conservative Model-Based Actor-Critic. arXiv preprint arXiv:2112.10504 (2021).
[2] Osband, Ian et al., Deep exploration via bootstrapped DQN. Advances in neural information processing systems 29 (2016): 4026-4034.
[3] Janner, Michael et al., When to trust your model: Model-based policy optimization. Advances in Neural Information Processing Systems 32 (2019): 12498-12509.
[4] Yu, Tianhe et al., Mopo: Model-based offline policy optimization. Advances in Neural Information Processing Systems 33 (2020): 14129-14142.
[5] Haarnoja, Tuomas et al., Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. International conference on machine learning. PMLR, 2018: 1856-1865.
[6] Chen, Xinyue et al., Randomized ensembled double q-learning: Learning fast without a model. arXiv preprint arXiv:2101.05982 (2021).
[7] Lim, Shiau Hong, Huan Xu, and Shie Mannor., Reinforcement learning in robust markov decision processes. Advances in Neural Information Processing Systems 26 (2013): 1325--1353.
撰稿人:夏钟升(2021级硕士生)
校稿人:刘嘉楠(2021级博士生)
")
